
You know what’s funny? Everyone is obsessed with how fast generative artificial intelligence can write a 2,000-word blog post, but almost nobody is talking about the wreckage it leaves behind in terms of brand integrity, legal liability, and search performance. The real risk of ai generated content isn't just a minor factual error here or there—it's a systemic degradation of trust that can quietly tank your business.
I've seen too many brands chase after AI content without considering how it dilutes their unique voice—authenticity still matters. In my ten years of managing digital campaigns, I've watched companies try to scale their output exponentially, only to see their engagement metrics plummet because their content read like a generic instruction manual. Most discussions around AI-generated content overlook the importance of human oversight; automated content can miss the nuances that connect with audiences.
Let's get real about what happens when you hand the keys of your content engine over to an algorithm.

TL;DR Summary
While generative AI promises unprecedented speed, its unmitigated use exposes organizations to severe technical, legal, and operational risks. From model collapse and automated spear phishing to copyright lawsuits and search index pollution, relying solely on synthetic output is a recipe for brand erosion. The solution lies in a hybrid model: leveraging AI for structural tasks while enforcing rigorous human oversight and verification.
Key Takeaways
• Technical Vulnerabilities: AI models suffer from inherent architectural flaws, including hallucinations and model collapse, which corrupt data integrity.
• Security Threats: Malicious actors use generative tools for prompt injection, data leakage, and highly convincing automated spear phishing.
• Legal Liabilities: Scraping-based training models face massive copyright and data privacy challenges under the GDPR and the EU AI Act.
• Industry Impacts: Healthcare, finance, and publishing face immediate, high-stakes risks from unverified synthetic information.
• Strategic Path Forward: Implementing Retrieval-Augmented Generation (RAG) and Human-in-the-Loop (HITL) workflows is non-negotiable for preserving brand authority.
Table of Contents
The Accuracy & Integrity Crisis (Technical Flaws)
Security & Threat Vectors (Malicious Use)
Legal, Regulatory & Compliance Risks
Societal & Ethical Fallout
Industry-Specific Vulnerabilities
Mitigation & The Path Forward (Actionable Solutions)
FAQ Section
The Accuracy & Integrity Crisis (Technical Flaws)

AI Hallucinations and the Citation Dilemma
Here’s the kicker: Large Language Models (LLMs) do not actually "know" anything. They are advanced statistical prediction engines designed to guess the next most probable word in a sequence. Because of this architecture, they regularly generate plausible-sounding but entirely fabricated information—commonly known as hallucinations.
This becomes incredibly dangerous when users rely on AI for research. LLMs will confidently cite non-existent court cases, invent medical studies, and generate fake URLs. According to the University of Florida Library GenAI Guide, verifying sources is absolutely critical because AI tools regularly output inaccurate citations that look authentic but have no basis in reality. If you publish these hallucinations, your brand's credibility is instantly shot.
Model Collapse & Data Degradation
What happens when AI starts training on AI-generated data? We get a phenomenon known as "model collapse." As the web becomes saturated with synthetic text, future generations of LLMs are trained on their own outputs rather than human-generated language.
This creates an echo chamber effect. Over time, the statistical variance of the model decreases, leading to a severe degradation of output quality. The language becomes repetitive, generic, and stripped of original insight. If you are relying on AI to build topical authority, you are essentially feeding your audience recycled, diluted ideas.
The "Black Box" Problem and Contextual Blindness
Another technical hurdle is the complete lack of explainability. When an AI model generates a recommendation or writes an analytical piece, it cannot show its work. There is no verifiable chain of reasoning.
This is coupled with profound contextual blindness. AI lacks the capacity to understand cultural nuances, sarcasm, or highly localized information. I once saw an automated campaign push a tone-deaf promotion during a localized natural disaster because the algorithm lacked the real-world context to pause the queue. Don’t just throw content out there—think it through!
Security & Threat Vectors (Malicious Use)
Prompt Injection & Jailbreaking
Security in the AI space is currently a game of whack-a-mole. Malicious actors have developed techniques called "prompt injection" and "jailbreaking" to bypass the safety guardrails established by AI developers. By structuring inputs in a specific, manipulative way, attackers can force an LLM to generate malicious code, write phishing emails, or reveal proprietary system instructions.
Data Privacy Leakage & Model Poisoning
Many businesses do not realize that when their employees paste proprietary code, financial spreadsheets, or sensitive patient data into public LLMs, that data may be ingested to train future iterations of the model. This is a massive corporate data leak waiting to happen.
Furthermore, there is the risk of model poisoning. This occurs when hackers intentionally feed corrupted or biased data into an open-source model's training set. Once the training data is poisoned, the model's future outputs can be manipulated to favor specific malicious outcomes or generate security vulnerabilities in code recommendations.
Automated Spear Phishing
Historically, phishing attacks were relatively easy to spot due to poor grammar, awkward phrasing, and generic greetings. Generative AI has completely eliminated those telltale signs. Attackers can now scale personalized social engineering campaigns at a fraction of the cost. By scraping public social media profiles, AI can generate highly tailored, grammatically perfect spear-phishing emails that are nearly indistinguishable from legitimate corporate communications.
Legal, Regulatory & Compliance Risks

The Compliance Comparison Matrix
To help you understand the complex regulatory environment surrounding synthetic media, I've compiled a breakdown of the primary legal risks, challenges, and the specific regulations governing them.
Risk Category | Key Challenge | Implicated Regulations |
|---|---|---|
Copyright Infringement | Models trained on protected intellectual property without consent; outputting copyrighted material. | US Copyright Office, Fair Use Doctrine |
Data Privacy Violations | Scraping Personally Identifiable Information (PII) to train models without user consent. | GDPR, CCPA |
Lack of Traceability | Inability to prove the origin or authenticity of synthetic content or automated decisions. | EU AI Act (Transparency Obligations) |
Liability & Defamation | Determining who is legally responsible when an AI tool defames an individual or entity. | Section 230 (US), India IT Rules |
Copyright Infringement & Fair Use
The legal battleground over AI training data is heating up. Major publishers and creators are suing AI companies for using their copyrighted works without compensation or permission. If your business publishes AI-generated content that closely mimics or directly reproduces copyrighted material, you could find yourself facing unexpected legal liabilities.
Furthermore, academic and professional standards require strict attribution. As detailed by the Yale Poorvu Center Plagiarism Guide, using ideas or text without proper citation constitutes plagiarism—a standard that AI tools routinely violate by presenting compiled human knowledge as their own novel output.
Traceability and the EU AI Act
Governments are starting to crack down on the Wild West of synthetic content. The European Union's AI Act, for example, imposes strict transparency obligations. If you use AI to generate or manipulate text, audio, or video, you must clearly label the output so users know they are interacting with synthetic media. Failing to build traceability into your content workflow could result in heavy regulatory fines.

Societal & Ethical Fallout
Algorithmic Bias & Discrimination
Because AI models are trained on historical human data, they inherit all of our societal biases. When these models are deployed to generate content, screen resumes, or make automated decisions, they often amplify those biases. This can lead to discriminatory outputs in hiring, lending, and public communications, exposing your brand to severe public backlash.

Deepfakes & Disinformation at Scale
The weaponization of synthetic audio and video is perhaps the most alarming societal risk. Deepfakes can be deployed to manipulate stock markets, disrupt political elections, or ruin individual reputations. When the cost of producing highly convincing fake media drops to zero, the shared epistemic foundation of society begins to crumble.
The AI Divide & Deskilling
There is a real danger of human deskilling. If writers, analysts, and junior employees rely entirely on AI to do their thinking and drafting, they stop developing critical thinking, research, and writing skills. There's a misconception that AI can fully replace human writers—I've found that the best results come from a hybrid approach where humans remain the driving creative force.
Industry-Specific Vulnerabilities

Healthcare & Finance Risks
In high-stakes industries, the margin for error is zero. In healthcare, relying on unverified AI outputs can lead to catastrophic medical advice or diagnostic errors. According to clinical evaluations published in NCBI PMC9997612, clinical decision support systems must undergo rigorous validation because unverified algorithmic outputs can compromise patient safety and violate regulatory standards.
In the financial sector, automated credit scoring and AI-driven market analysis can perpetuate discrimination or trigger flash crashes due to algorithmic feedback loops.
Education & Publishing (Search Index Pollution)
In the publishing world, we are witnessing a massive wave of content farming. Low-quality, programmatic websites are pumping out thousands of AI-generated articles daily to capture search traffic. This has led to severe search index pollution.
To combat this, search engines are rapidly evolving. Understanding the differences between Traditional SEO vs AI SEO is crucial for survival. While traditional SEO focused on keyword density and basic backlinks, search engines now actively penalize low-effort, automated content that lacks real-world expertise and original perspective.
Mitigation & The Path Forward (Actionable Solutions)
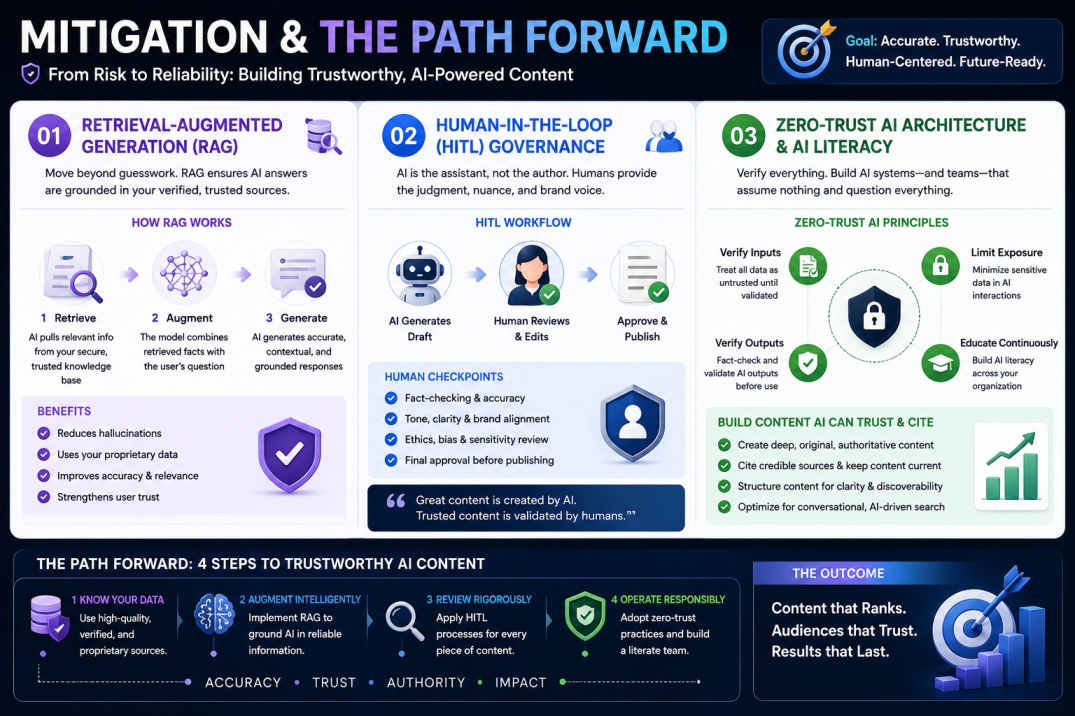
Retrieval-Augmented Generation (RAG)
To combat the accuracy crisis, organizations must move away from raw, ungrounded LLMs. The industry standard for accuracy is Retrieval-Augmented Generation (RAG). RAG forces the AI model to retrieve information from a closed, verified database of your own documents before generating an answer. This dramatically reduces hallucinations and ensures that the output is grounded in actual facts.
When verifying external facts, you should employ structured evaluation frameworks. As outlined in the GFC MSU Library Source Evaluation Guide, checking the authority, accuracy, and currency of your sources is the only way to ensure your content remains trustworthy and authoritative.
Human-in-the-Loop (HITL) Governance
Don’t just throw content out there—think it through! A robust Human-in-the-Loop (HITL) governance model is non-negotiable. Every piece of AI-assisted content must go through a human editor who checks for tone, accuracy, and brand alignment.
For instance, while you might discover Why Use AI for Keyword Research saves hours of manual analysis, the actual content creation and final editing must retain that irreplaceable human touch to resonate with readers.
Zero-Trust AI Architecture & AI Literacy
Organizations must adopt a zero-trust posture toward AI inputs and outputs. Treat every piece of data generated by an AI as potentially compromised or inaccurate until verified. Furthermore, as search engines move toward conversational, AI-driven models, brands must focus on Optimizing for Perplexity in AI Search by building deep, authoritative content that AI engines will trust and cite.
FAQ Section
Q: Can search engines detect AI-generated content?
• Yes. Search engines use highly sophisticated classifiers to identify patterns common in synthetic text. However, their primary focus is on quality over quantity. If your content is helpful, original, and accurate, it can rank well regardless of how it was drafted.
Q: What is the biggest legal risk of using AI for content creation?
• The primary legal risks are copyright infringement and data privacy violations. If an AI tool outputs copyrighted text or incorporates protected personal data without consent, your company can be held liable.
Q: How do we prevent AI hallucinations in our business content?
• Implement a strict Human-in-the-Loop (HITL) review process, ground your models using Retrieval-Augmented Generation (RAG) with internal databases, and mandate that all factual claims are verified against authoritative external sources.
Sources and References
• University of Florida Library: Generative AI FAQ
• GFC MSU Library: Evaluating Sources Guide
• Yale Poorvu Center: Understanding and Avoiding Plagiarism
• National Institutes of Health (NIH): AI Safety & Validation Study


