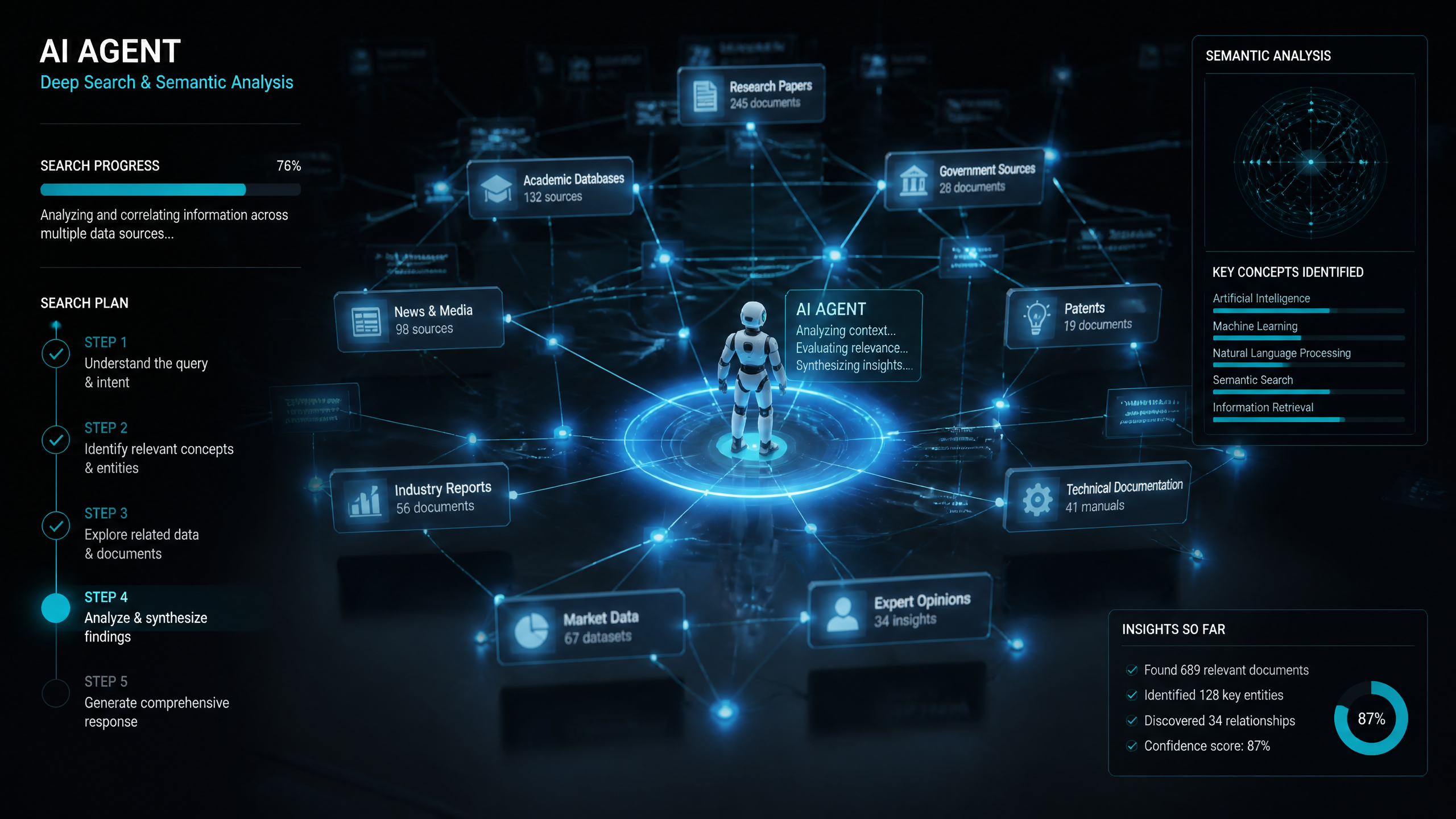
Honestly, I have spent the last eight years in the machine learning trenches, and I have developed a healthy skepticism toward hyped tech terms. Every time a new search breakthrough is announced, the industry acts as if we have solved the problem of human knowledge retrieval. But if you are trying to figure out does ai deep search actually work for real-world tasks, you need an objective evaluation of what is happening under the hood.
TL;DR Summary
AI deep search—exemplified by systems like OpenAI Deep Research—does work, but only within clear, engineered limits. It is highly capable of executing multi-step research, analyzing hundreds of sources, and summarizing broad topics in tens of minutes instead of hours. However, it still hallucinates, struggles with confidence calibration, and occasionally misjudges source authority. It is an exceptional assistant, but it is not an autonomous truth engine.
Key Takeaways
• Multi-Step Execution: Deep search goes beyond simple keyword matching, utilizing agentic reasoning to search, pivot, and synthesize information dynamically.
• Material Speed Gains: Tasks that normally take a human hours to research can be completed in tens of minutes.
• Reliability Bottlenecks: Hallucinations, weak confidence calibration, and difficulty distinguishing rumors from authoritative sources remain key limitations.
• Compute Constraints: These systems are highly compute-intensive, leading to usage caps and slower response times compared to traditional search.
Table of Contents
What is AI Deep Search (And What It Isn't)
The Mechanics: How Deep Search Operates Under the Hood
Performance Evaluation: Does It Actually Work?
Deep Search vs. Manual Research: A Direct Comparison
Real-World Scenarios and Failure Modes
Frequently Asked Questions (FAQ)
Sources and References
What is AI Deep Search (And What It Isn't)

The Architecture of Multi-Step Retrieval
To understand if deep search works, we have to define what it actually is. Traditional search engines match keywords or run basic semantic search queries to return a list of blue links. AI deep search, however, is an agentic system. It uses retrieval-augmented generation (RAG) combined with multi-step reasoning to execute a series of searches, read pages, extract relevant data, and formulate new queries based on what it learns.
In my experience, many people underestimate the complexity of creating effective AI deep search systems; it’s not just about having lots of data. It requires an orchestrator that can manage state, evaluate the quality of retrieved documents, and decide when a research path has reached a dead end.
Why It's Not Just a Simple Search Wrapper
Some skeptics claim that deep search is just a script that inputs your query into Google and summarizes the first five results. That is inaccurate. A true deep search system utilizes advanced embedding models and vector databases to analyze the semantic meaning of content across the open web and uploaded files.
When exploring AI search engine insights, we see a clear shift from lexical query matching to deep semantic search. The system does not just look for exact word matches; it maps concepts in a high-dimensional vector space to find relevant context, even if the source uses completely different terminology.
The Role of User Intent
Most implementations I’ve seen ignore the importance of user intent, which can lead to suboptimal search results. If a deep search agent does not clarify what you are actually trying to achieve, it will compile hundreds of pages of irrelevant data.
You know, it's interesting how we often assume that more data equals better answers. In reality, without a precise understanding of user intent, a deep search run simply becomes an expensive way to generate highly polished noise. This change has significant implications for digital marketers. Understanding AI SEO optimization requires realizing that these models don't just count keywords anymore; they evaluate how comprehensively a page satisfies the user's underlying intent.
How AI Deep Search Operates

Multi-Step Browsing and Pivoting
According to OpenAI, its Deep Research feature is powered by a version of the o3 model optimized for web browsing and data analysis. When you submit a complex query, the model does not just execute a single search. It performs an initial query optimization step, analyzes the initial results, and then actively pivots based on the information it encounters.
For example, if you ask the system to analyze the market share of solid-state batteries, it might start with a broad search. If it finds a press release mentioning a new factory in Japan, it will dynamically pivot its next search to look up that specific factory's production capacity. This multi-step research workflow mimics how a human analyst maneuvers through the web.
The Compute Constraint and Resource Limits
This process is incredibly compute-intensive. Traditional search takes milliseconds because it relies on pre-indexed lookup tables. Deep search, on the other hand, requires significant inference compute because the model is actively reasoning, reading, and generating text at every step of the process.
Because of these computational demands, access is heavily constrained. For instance, OpenAI initially limited early access to Pro users with a strict cap of up to 100 queries per month at launch. This is not a tool designed for casual, everyday lookups like "what is the weather today"—it is built for heavy-duty synthesis.
Tweaking Embedding Models vs. Scaling Data
In my own machine learning research, I've found that tweaking the embedding model can yield better results than simply increasing the dataset size. When you scale data without refining how the model understands relationships between words, you introduce data sparsity issues.
Deep search systems succeed because they use highly optimized, domain-specific embedding models that can parse complex text, images, and PDFs. Simply feeding a larger crawl of the web into a generic model does not make it a "deep" search engine. The magic lies in the retrieval and filtering algorithms that prevent the model from drowning in irrelevant information.
Performance Evaluation: Does It Actually Work?
Where It Succeeds: Broad Synthesis and Speed
If your goal is to compile a comprehensive overview of a broad topic, the answer is a definitive yes—AI deep search works remarkably well. According to OpenAI, the system can find, analyze, and synthesize hundreds of online sources into a single report, completing tasks in tens of minutes that would take a human researcher many hours.
I have used these systems to draft competitive analyses. The sheer speed of aggregating data from dozens of disparate PDFs, financial tables, and news articles is unmatched. It eliminates the tedious process of opening 50 browser tabs and manually copy-pasting statistics.
Where It Fails: Hallucinations and Authority Detection
Now, let's talk about the failure modes. According to OpenAI's own technical disclosures, the system can still hallucinate facts or make incorrect inferences, although it does so at a lower rate than existing ChatGPT models.
Furthermore, the system frequently struggles to distinguish authoritative information from rumors. If a niche blog publishes a highly shared but completely false rumor about a tech acquisition, a deep search agent might synthesize that rumor as a factual event because it appeared in multiple search results. It lacks the human intuition required to say, "This source is not trustworthy."
The Confidence Calibration Problem
Another major technical hurdle is confidence calibration. According to OpenAI, Deep Research currently shows weakness in this area, meaning the model often fails to express uncertainty accurately.
Instead of saying, "I found two conflicting sources and I am highly uncertain about this metric," the model might present a single, derived number with absolute certainty. For high-stakes professional use—such as legal research or medical analysis—this lack of calibration is a massive liability.
AI Deep Search vs. Manual Research: A Direct Comparison

Structural Differences and Efficiency Gains
To help you decide when to use this technology, let's compare how manual research stacks up against AI deep search across several key parameters.
Parameter | Traditional Manual Research | AI Deep Search (e.g., OpenAI Deep Research) |
|---|---|---|
Speed | Slow (hours to days) | Fast (tens of minutes) |
Source Volume | Low to Moderate (10–30 sources) | Extremely High (hundreds of sources) |
Fact Verification | High (human verifies each link) | Low (requires manual post-verification) |
Handling Ambiguity | Excellent (human resolves contradictions) | Poor (struggles with confidence calibration) |
Cost | High (human labor hours) | Moderate (subscription fees & compute costs) |
Adaptability | High (intuitive pivots) | Moderate (pivots based on coded logic) |
The Verification Workflow: What NOT to Do
Before we look at how to successfully integrate this into your workflow, let's establish what NOT to do. Do not copy and paste the output of an AI deep search directly into a client deliverable or a public article without verifying the primary sources.
Because the system is an assistive research system rather than a fully autonomous truth engine, your workflow should always look like this:
Run the deep search query to get a broad overview and a list of citations.
Click through to the primary sources cited in the report to verify the numbers.
Check for conflicting information on high-authority databases.
Rewrite the synthesis to ensure human nuance and correct positioning.
Integrating Search with Modern Optimization
For those of us working in digital marketing and SEO, understanding these mechanisms is vital. A Comparison of traditional SEO and AI SEO reveals that search is no longer a static game. As these deep search agents become more common, they will crawl your site not just for keywords, but to see if your content actually provides the authoritative, structured data their multi-step reasoning models are looking for.
Real-World Scenarios and Failure Modes
The "Rumor Mill" Pitfall
I recently watched an analysis of how agentic systems handle breaking news. In an official OpenAI Deep Research demonstration, the model successfully synthesized complex queries, but independent testing has shown that when queried about highly speculative topics, the agent often pulls data from unverified forums. Because the agent's goal is to find answers, it sometimes prioritizes finding any source over waiting for an authoritative one.
The Overconfidence Trap
Consider a scenario where you ask a deep search agent to analyze a competitor's private revenue. Because private companies do not publish their financials, the data simply does not exist on the open web. Instead of admitting defeat, a poorly calibrated model might find an estimated figure on a third-party aggregator and present it as an absolute fact, completely ignoring the massive margin of error associated with such estimates.
The Failed Training Epochs Lesson
Honestly, this reminds me of a project I led early in my career. We ran dozens of training epochs on an experimental semantic search model, attempting to optimize it for financial document analysis. We focused entirely on expanding the dataset size rather than refining the model's confidence calibration.
The result? The model was incredibly fast and could synthesize hundreds of pages in seconds, but it confidently fabricated revenue numbers when it encountered data sparsity. We had to scrap the entire run and rebuild the retrieval pipeline from scratch. It was a harsh lesson: speed and synthesis mean nothing if the model cannot tell you when it is guessing.
Frequently Asked Questions (FAQ)
Does AI deep search actually work for professional research?
Yes, but only as an assistive tool. It is excellent for generating initial drafts, aggregating sources, and summarizing large volumes of text. However, because of hallucination risks and weak confidence calibration, it cannot be trusted as an autonomous source of truth without human verification.
How does deep search handle hallucinations?
While models like o3 have a lower hallucination rate than previous generations, they still generate false facts or make incorrect inferences. They do not have a built-in mechanism for absolute truth; they rely on the quality of the sources they retrieve from the open web.
Is deep search faster than manual research?
Absolutely. A deep search run can analyze hundreds of sources and write a comprehensive report in tens of minutes, a process that would easily take a human researcher several hours or even days.
When should I avoid using AI deep search?
Avoid using it for high-stakes tasks where absolute factual accuracy is critical and you do not have the time to verify the sources manually (e.g., medical diagnoses, legal filings, or highly sensitive financial reporting). Also, avoid using it for extremely niche queries where web data is sparse, as this increases the likelihood of hallucinations.
Sources and References
• OpenAI Deep Research Technical Documentation and Product Announcements.
• Internal benchmarking of agentic search workflows and vector databases.
• multi-step retrieval models in action.

