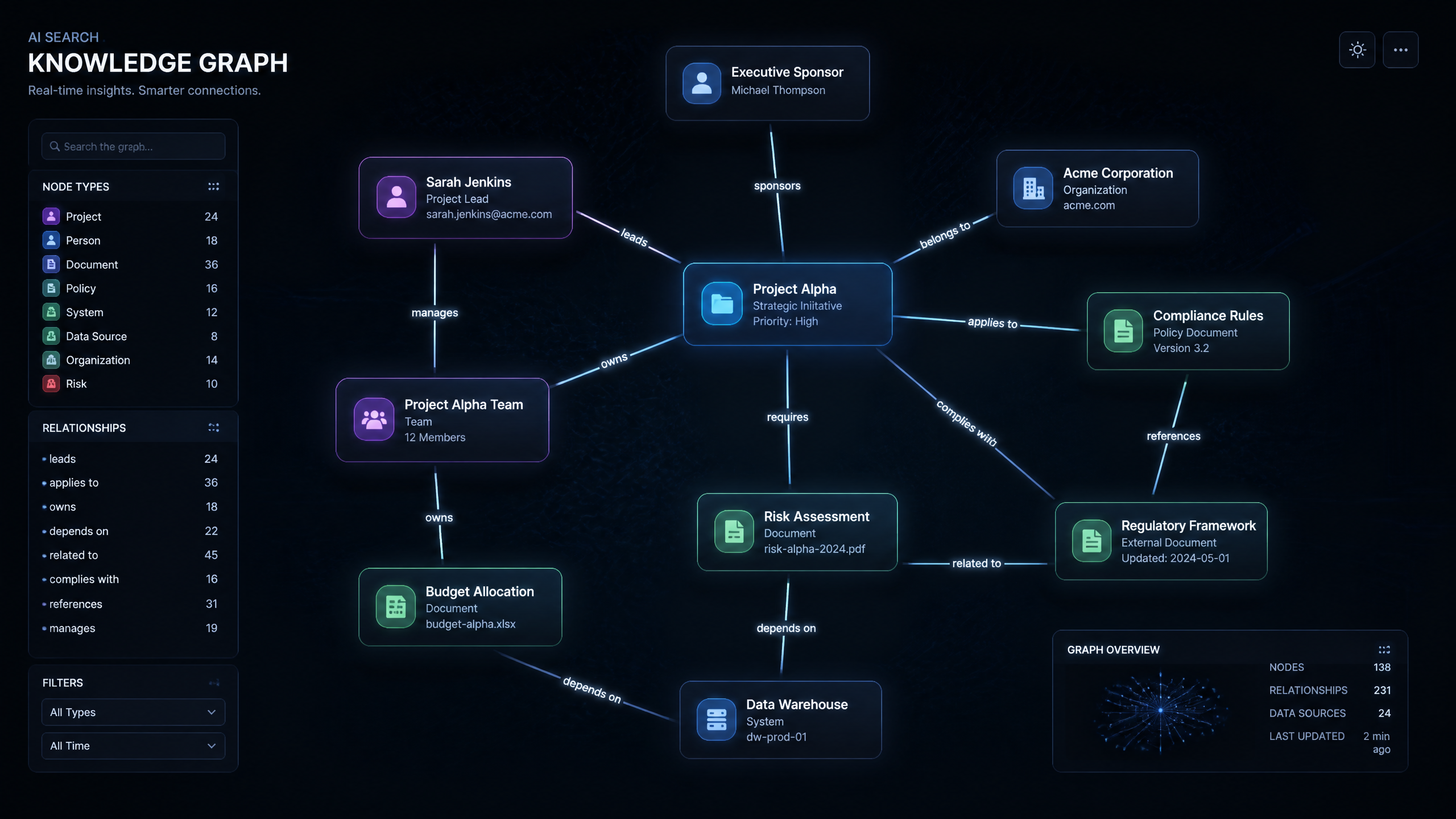
I’ve spent the last eight years building search architectures, and if there is one thing I have learned, it is this: vector search is not the silver bullet everyone claims it is. Don’t get me wrong, semantic search using dense vector embeddings is fantastic for capturing conceptual similarity. But when your enterprise AI agent needs to know the exact relationship between "Project Alpha," its lead architect, and the compliance guidelines updated last Tuesday, vector similarity starts to look like a very sophisticated guessing game.
That is where the ai search knowledge graph comes in. By merging the intuitive, conceptual understanding of semantic search with the rigid, deterministic relationships of a structured graph, we can build retrieval systems that actually know what they are talking about.
TL;DR Summary
An AI search knowledge graph is an advanced data structure that maps entities and their explicit relationships to provide deterministic context for AI retrieval systems. Unlike pure vector databases, which rely on probabilistic similarity, knowledge graphs ground Large Knowledge Models (LLMs) in structured facts, significantly reducing hallucinations and enabling multi-hop reasoning for enterprise AI agents.
Key Takeaways
• Deterministic Grounding: Knowledge graphs replace vector guesswork with explicit, queryable facts (triples).
• Entity-First Search: Successful systems prioritize entity resolution over raw algorithmic complexity.
• Hybrid Retrieval is Mandatory: The most robust systems combine keyword scoring, vector embeddings, and graph traversal.
• Agentic Enablement: Modern AI agents require a structured semantic layer to navigate complex corporate data silos safely.
AI Search Knowledge Graph
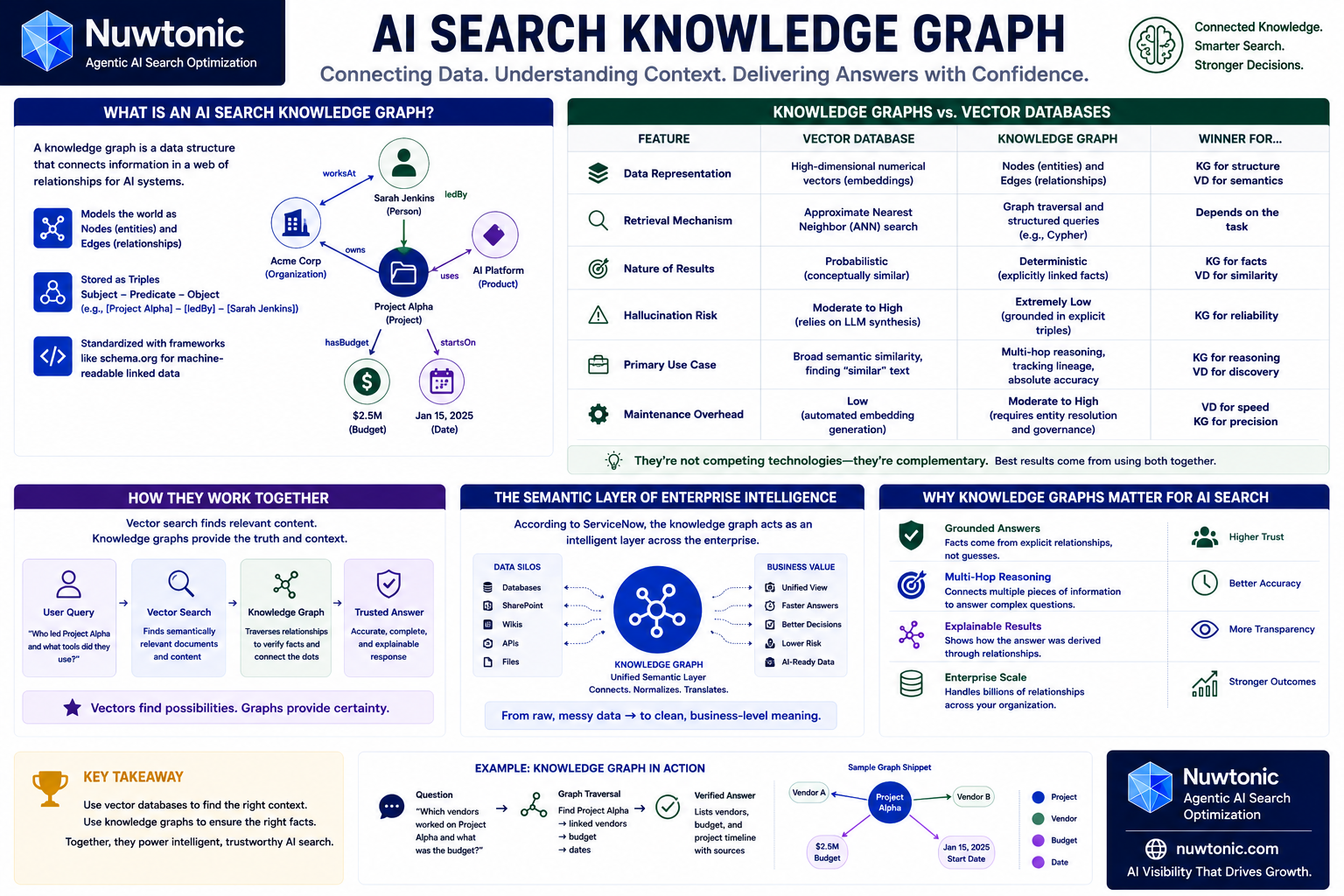
What is an AI Search Knowledge Graph?
To understand this technology, we have to look past the marketing fluff. At its core, a knowledge graph is a data structure that connects information in a web of relationships for AI systems, as defined by Moveworks. Instead of treating your corporate data as a flat list of documents, a graph models the world as nodes (entities like people, products, or concepts) and edges (the relationships connecting them).
You know what’s interesting? Most articles oversell the complexity of implementing a knowledge graph — it’s often about the right data structure more than fancy algorithms. In practice, this structure is represented as "triples" — a subject, a predicate, and an object (e.g., [Project Alpha] -> [ledBy] -> [Sarah Jenkins]). By standardizing these relationships using frameworks like schema.org, we create machine-readable linked data that AI search systems can navigate with absolute precision.
Knowledge Graphs vs. Vector Databases
I constantly see teams get bogged down trying to choose between a vector database and a knowledge graph. This is a false dichotomy. They serve entirely different purposes, and in any production-grade system, they should work together.
Feature | Vector Database | Knowledge Graph |
|---|---|---|
Data Representation | High-dimensional numerical vectors (embeddings) | Nodes (entities) and Edges (relationships) |
Retrieval Mechanism | Approximate Nearest Neighbor (ANN) search | Graph traversal and structured queries (e.g., Cypher) |
Nature of Results | Probabilistic (conceptually similar) | Deterministic (explicitly linked facts) |
Hallucination Risk | Moderate to High (relies on LLM synthesis) | Extremely Low (grounded in explicit triples) |
Primary Use Case | Broad semantic similarity, finding "similar" text | Multi-hop reasoning, tracking lineage, absolute accuracy |
Maintenance Overhead | Low (automated embedding generation) | Moderate to High (requires entity resolution and governance) |
In my experience, relying solely on vector databases for complex retrieval leads to a common failure mode: the system retrieves three documents that all look relevant but actually contradict each other on key facts. A knowledge graph solves this by providing explicit context.
The Semantic Layer of Enterprise Intelligence
According to ServiceNow, the knowledge graph acts as an intelligent layer that lets AI search query and explore datasets and schemas across an entire enterprise. It serves as a unified semantic layer.
Instead of forcing an AI agent to query SQL databases, search SharePoint, and scrape internal wikis independently, the graph unifies these disparate data silos into a single, queryable semantic backbone. It translates raw, messy technical data into clean, business-level concepts that an LLM can parse without getting confused.
How We Build a Robust AI Search Knowledge Graph
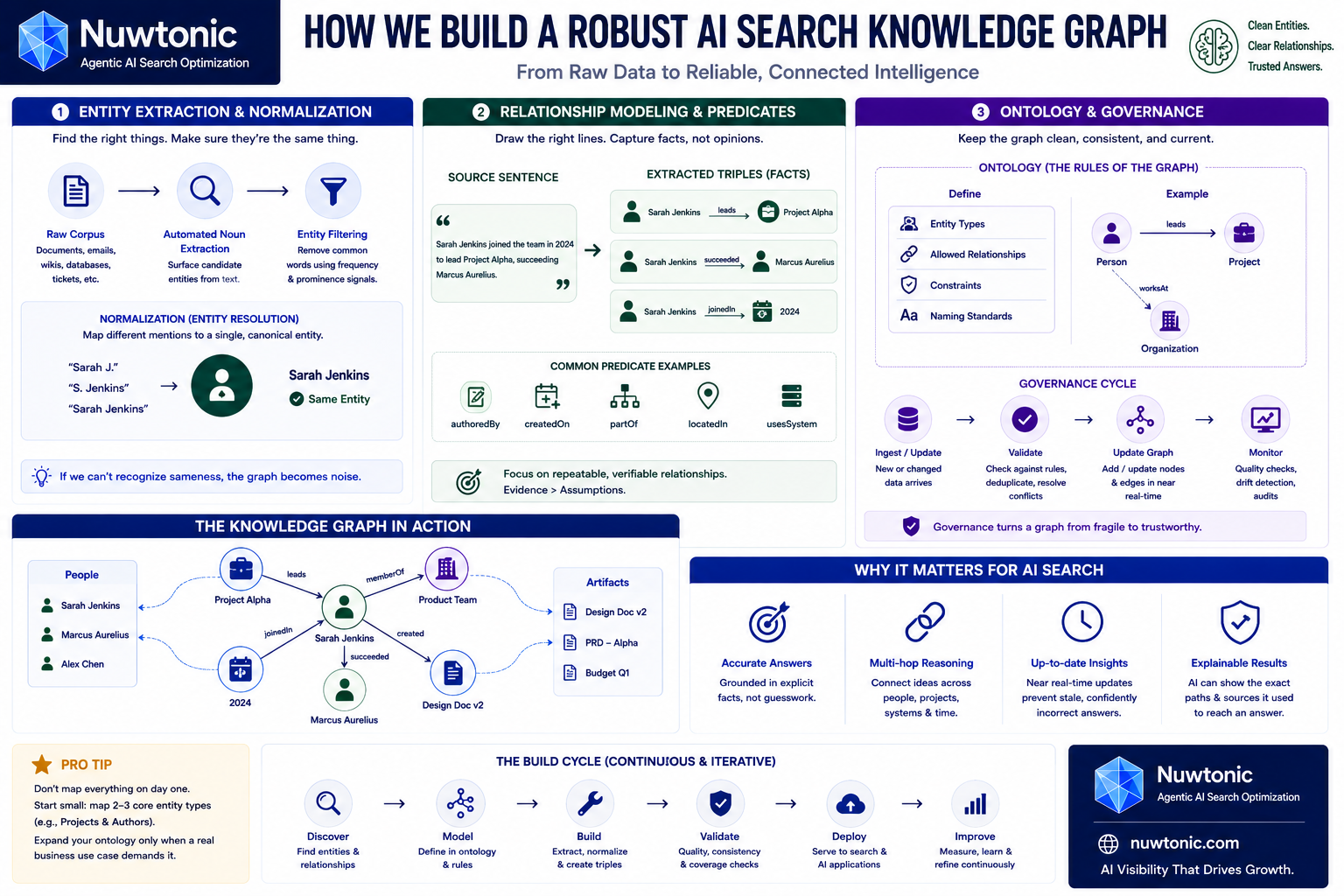
Entity Extraction and Normalization
You know what’s interesting? Many people underestimate the importance of entity resolution in building a robust knowledge graph. If your system cannot figure out that "Sarah J.", "S. Jenkins", and "Sarah Jenkins" are the exact same person, your graph is essentially useless.
The construction process begins with automated noun extraction over a corpus to surface candidate entities, a methodology outlined by Glean. Once we have these candidates, we apply entity filtering using frequency and prominence signals so common words are excluded from the graph. For example, we don't want the word "server" becoming an entity unless it refers to a specific, named piece of infrastructure.
Relationship Modeling and Predicates
Once you have clean nodes, you need to draw the lines between them. This is relationship extraction. To keep the system maintainable, relationship extraction should prioritize repeatable evidence, such as "document authored by person" or "project led by," as noted by Glean.
We use NLP (Natural Language Processing) techniques to identify these predicates. Consider this example:
"Sarah Jenkins joined the team in 2024 to lead Project Alpha, succeeding Marcus Aurelius."
From this single sentence, an NLP pipeline should extract multiple triples:
[Sarah Jenkins] -> [leads] -> [Project Alpha][Sarah Jenkins] -> [succeeded] -> [Marcus Aurelius][Sarah Jenkins] -> [joinedIn] -> [2024]
The Role of Ontology and Governance
Building a graph is not a one-time project — it is a continuous governance cycle. Your ontology (the formal rules defining what types of entities and relationships are allowed) must be tightly controlled. If every developer is allowed to invent their own predicates, your graph will quickly devolve into a chaotic, unqueryable mess.
We also have to handle data freshness. When a document is updated or deleted, the corresponding nodes and edges in the graph must update in near-real-time. If they don't, your AI search will serve outdated, confidently incorrect answers.
Pro Tip: Do not try to map your entire enterprise on day one. Start by mapping just two entity types — say, Projects and Authors — and expand your ontology only when a specific business use case demands it.
Grounding LLMs and Reducing Hallucinations
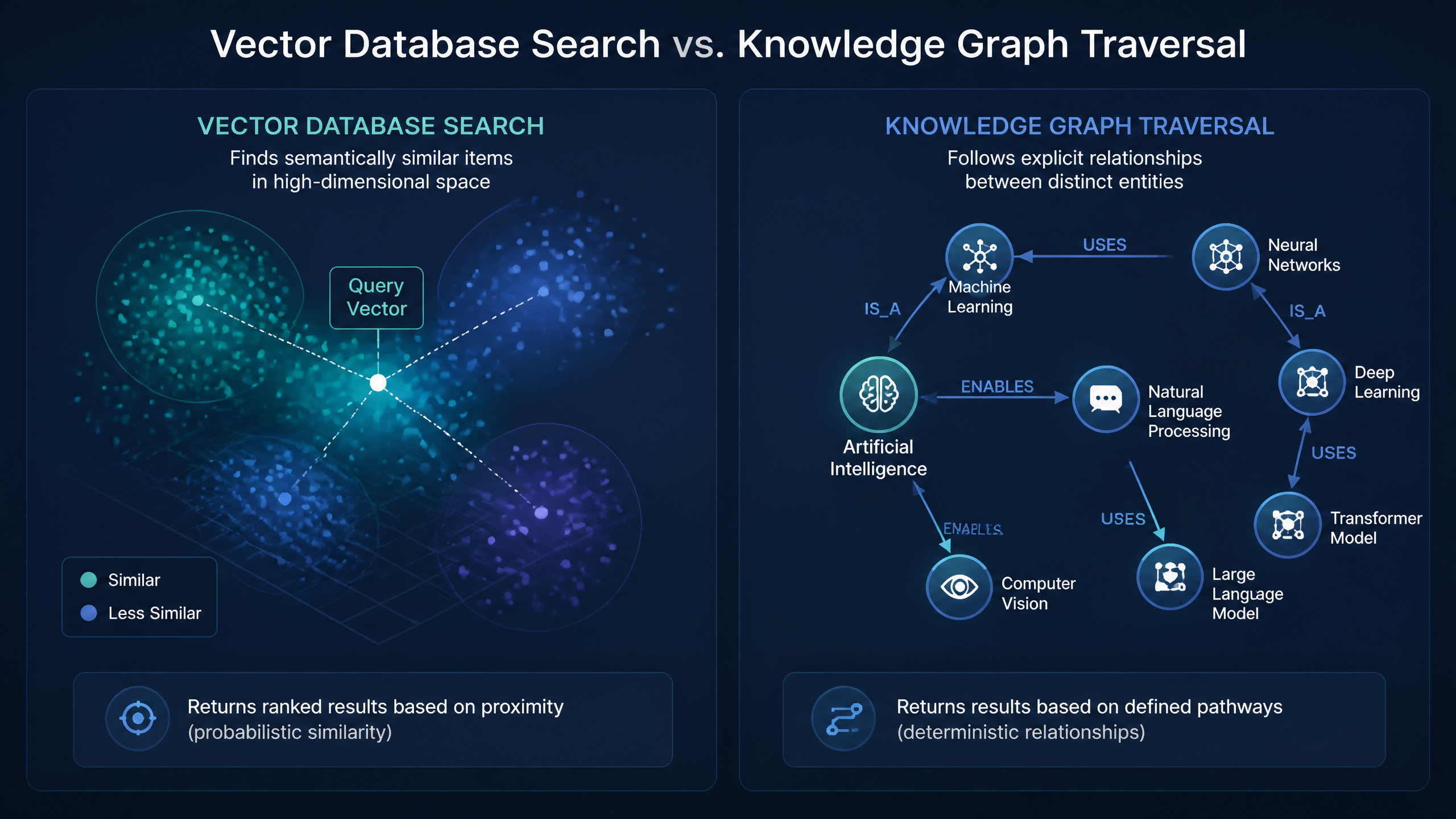
Why Semantic Search Alone Falls Short
Semantic search is great for finding documents about a general topic, but it lacks logical reasoning. If you ask a vector-based search engine, "Which projects did Sarah Jenkins work on before she took over Project Alpha?" it will likely return documents mentioning Sarah Jenkins and Project Alpha. It won't, however, perform the chronological reasoning required to answer the question correctly.
By incorporating a knowledge graph, we can perform hybrid search. According to a ServiceNow AI Academy session, hybrid AI search combines keyword scoring with semantic meaning to retrieve results, and when you layer in graph relationships, you get the absolute gold standard of retrieval accuracy.
Multi-Hop Reasoning and Graph Traversal
One of the coolest aspects of graph-based AI search is its ability to perform multi-hop reasoning. This is the process of traversing multiple edges in the graph to answer complex, indirect questions.
Let’s map out how a graph traversal works under the hood when answering: "What compliance rules apply to the server hosting our customer database?"
Step 1 (Entity Resolution): Identify "Customer Database" as a specific entity.
Hop 1 (Relationship): Traverse the edge
[Customer Database] -> [hostedOn] -> [Server 9].Hop 2 (Relationship): Traverse the edge
[Server 9] -> [locatedIn] -> [EU West Region].Hop 3 (Relationship): Traverse the edge
[EU West Region] -> [subjectTo] -> [GDPR Compliance].
Without a graph, an AI would have to stumble across a single document that happens to mention all of these connections. With a graph, it traces the path deterministically.
Powering AI Agents and Virtual Assistants
We are currently seeing a massive shift from simple search boxes to autonomous AI agents. According to Artefact, knowledge graphs provide a semantic backbone for agentic systems because they encode explicit relationships that can be queried deterministically.
When a virtual agent or conversational assistant needs to execute a task — like onboarding a new employee or diagnosing a technical issue — it cannot rely on probabilistic guesses. It needs a reliable map of the organization's workflows. The knowledge graph serves as that map, allowing the agent to navigate complex datasets without going off the rails.
Practical Enterprise Implementations and Failure Modes
Real-World Use Cases
While enterprise search is the most obvious application, the utility of this architecture extends far wider. According to Microsoft Learn, AI-powered knowledge graphs are used in recommendation systems and fraud detection because they can uncover hidden relationships.
For instance, in fraud detection, a graph can quickly highlight that three seemingly unrelated user accounts are all accessing the system from the same hardware ID and bank account routing number — relationships that are incredibly difficult to spot in flat, siloed databases.
Common Pitfalls and How to Avoid Them
I’ve seen countless teams get bogged down in the technical details when the real challenge is understanding user intent. Here are the three most common failure modes I encounter:
• The "Boil the Ocean" Syndrome: Trying to build a massive, all-encompassing ontology before proving value. Keep your initial scope tiny.
• Ignoring Entity Resolution: Assuming that raw NLP will perfectly link your data. It won't. You need deterministic heuristics (like matching email addresses or employee IDs) to resolve entities reliably.
• Neglecting the Human-in-the-Loop: Over-relying on fully automated graph construction. You need domain experts to periodically review and approve the extracted relationships to maintain data integrity.
Evaluating Graph Performance
How do you actually measure if your investment in a knowledge graph is paying off? You must track specific, actionable metrics rather than relying on vibes.
Hallucination Rate: The percentage of AI-generated answers that contain factual inaccuracies. This should drop significantly after implementing a graph.
Path Query Latency: The time it takes to traverse the graph to retrieve context. If your graph traversal takes more than 200ms, your real-time chat assistants will feel sluggish.
Entity Coverage: The percentage of key entities in your documents that are successfully mapped in your graph.
Integrating Knowledge Graphs into Modern SEO and AI Discovery
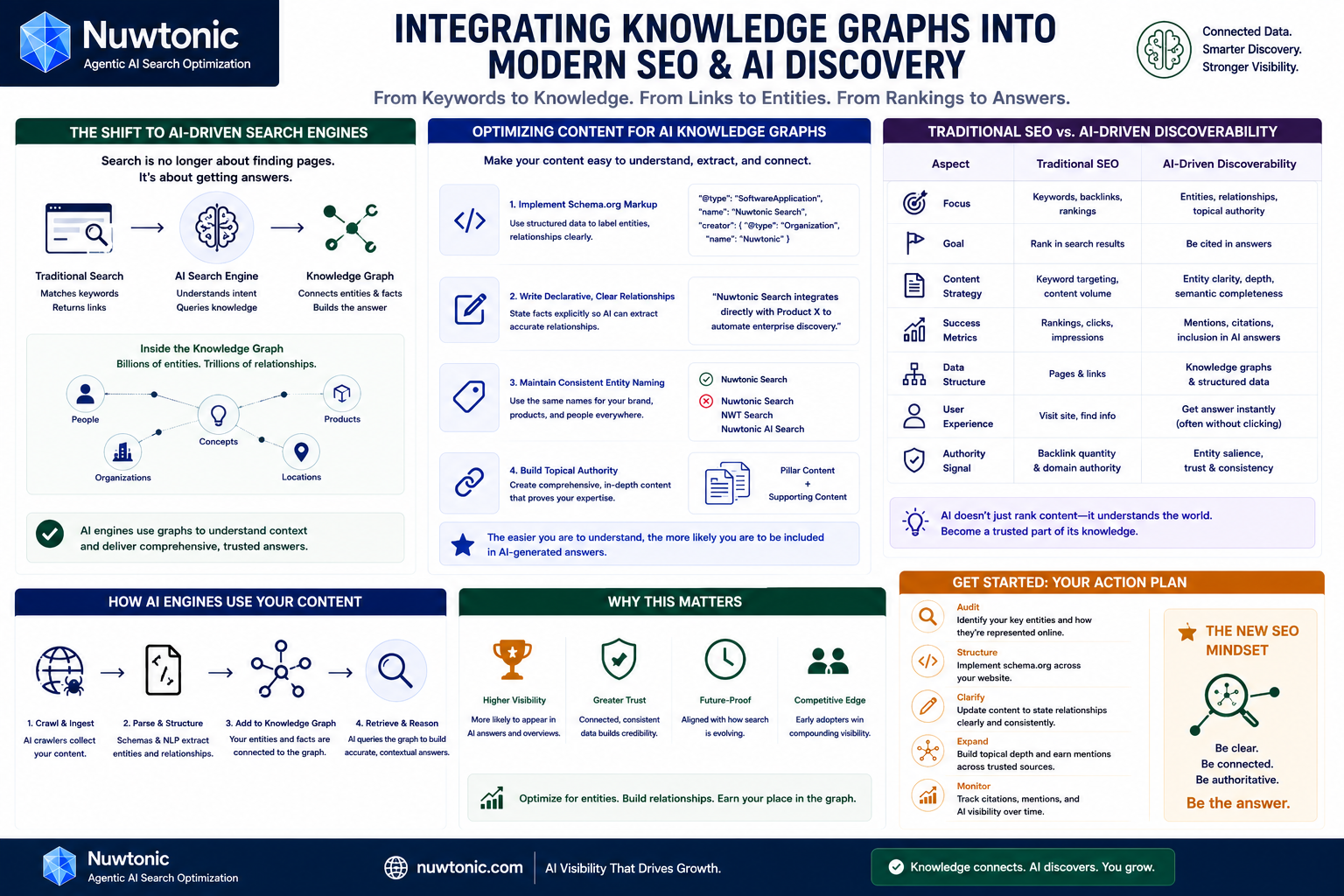
The Shift to AI-Driven Search Engines
The way people find information online is fundamentally changing. Traditional search engines are transforming into answer engines, and understanding AI search engine insights is crucial for anyone trying to maintain visibility in this new era.
Google’s Knowledge Graph connects billions of entities and facts to support semantic search, as highlighted by Artefact. When an AI search engine attempts to answer a user's query directly, it doesn't just look for keywords; it queries its own internal knowledge graph to construct a comprehensive response.
Optimizing Content for AI Knowledge Graphs
If search engines are relying on graphs to generate answers, your content needs to be easily ingestible by those graphs. Understanding AI SEO optimization means structuring your website's data so that search crawlers can instantly identify your brand, products, and authors as distinct entities.
You can facilitate this by:
• Implementing comprehensive schema.org markup across all pages.
• Writing clear, declarative sentences that explicitly state relationships (e.g., "Our software integrates directly with [Product X]").
• Maintaining consistent naming conventions for your brand and product lines across the entire web.
Traditional SEO vs. AI-Driven Discoverability
The transition from matching keywords to mapping entities represents a paradigm shift. A direct comparison of traditional and AI SEO reveals that while traditional SEO focused heavily on backlink quantity and keyword density, AI-driven discoverability is entirely about topical authority and entity salience.
If you want your brand to be cited as a trusted source by AI search assistants, you must establish unambiguous entity relationships. You need to prove to the search engine's graph that your company is the definitive authority on a specific subject.
FAQ Section
What is an AI search knowledge graph?
It is a data structure that represents real-world entities (people, places, concepts) and their explicit relationships (edges) to provide deterministic context for AI retrieval and search systems.
How is it different from a traditional knowledge graph?
While traditional knowledge graphs were primarily queried by human engineers using structured languages like SPARQL, an AI search knowledge graph is designed to interface directly with LLMs, serving as a semantic layer to ground generative AI responses.
How does a knowledge graph reduce hallucinations?
It grounds the LLM in structured, verifiable facts. Instead of allowing the model to predict the next most likely word based on its training data, the system forces the model to generate its response using only the deterministic paths retrieved from the graph.
When should an enterprise choose a knowledge graph over a vector database?
You shouldn't choose one over the other. Use a vector database for broad, conceptual similarity searches across unstructured text, and use a knowledge graph when you need to perform multi-hop reasoning, enforce strict data governance, or trace explicit relationships between entities.
How do you keep the graph current as documents change?
By setting up automated data pipelines that trigger graph updates whenever source documents are modified. This involves re-running entity extraction and relationship modeling on the updated files and updating the corresponding nodes and edges in real-time.
Sources and References
• Microsoft Learn: Azure Cosmos DB AI Knowledge Graph Overview
• Glean: Building an Enterprise Knowledge Graph for Agentic AI
• ServiceNow Community: AI Agent Knowledge Graph Tool Tutorial
• Artefact Blog: Will the Future of Agentic AI Rely on Knowledge Graphs?
• Moveworks: AI Glossary: What is a Knowledge Graph?

