
AI search has changed the win condition. A top organic ranking no longer guarantees visibility if the model cannot extract a clean answer, verify the source, and cite the page with confidence.
Teams that treat AI search optimization as a writing task miss the operational reality. Citation eligibility depends on how the page is designed, how facts are sourced, how entities are defined, how structured data is implemented, and whether the page can be crawled and rendered without friction. Strong copy helps, but it is only one layer.
The practical approach is an end-to-end workflow: shape content so answers can be lifted cleanly, support claims with verifiable sources, publish markup that matches the page, keep technical SEO clean, and monitor citation loss at the URL level. Platforms like Nuwtonic turn that workflow into assigned tasks, recurring checks, and remediation loops instead of a one-time editorial pass.
That is the standard for discoverability in AI search now.
Table of Contents
- The New Rules of Discoverability in AI Search
- Adopting an Entity-First Content Design
- Implementing Technical Structured Data
- Building Source Authority and Citation Hygiene
- Ensuring Technical Readiness and AI Indexing
- Monitoring AI Visibility and Iterative Remediation
- Frequently Asked Questions about AI Search Optimization
The New Rules of Discoverability in AI Search
Traditional SEO asked one main question. Can a user find your page in a ranked list?
AI search asks a different one. Can a model isolate a clean answer, verify enough trust signals, and cite the page without ambiguity? That's a harsher standard because the model isn't browsing your article the way a person does. It's extracting fragments under time and context limits.
The practical shift is from keyword-first pages to entity-first pages. A keyword-first page often circles the topic, adds long intros, and spreads the actual answer across multiple paragraphs. An entity-first page names the topic clearly, states the answer early, and organizes supporting facts into units a retrieval system can lift without rewriting your meaning.
Practical rule: If a paragraph needs the previous three paragraphs to make sense, it's hard for an AI system to cite safely.
That changes what “discoverability” means.
- Human discoverability: a searcher clicks, scans, and decides whether to trust you.
- Machine discoverability: a model identifies the main entity, maps related entities, pulls an answer chunk, and checks whether the source feels stable and citable.
- Operational discoverability: your team can keep the page current as interfaces, prompts, and competitors change.
A lot of pages fail in the middle layer. They rank. They even convert. But they aren't built for extraction. They use vague headings, bury definitions, and treat structure as formatting instead of retrieval infrastructure.
To optimize content for AI search, treat every page as a set of reusable answer modules. Each module should answer one question, define one concept, compare one choice, or explain one process. Then the technical layer has to confirm that structure in HTML and schema. Finally, monitoring has to show whether models are citing the page, not just whether impressions look healthy.
That's the new bar. Visibility now depends on being easy to parse, easy to trust, and easy to refresh.
Adopting an Entity-First Content Design
The fastest way to lose an AI citation is to make the model work too hard to find the answer. Most legacy blog posts do exactly that. They open with scene-setting, delay the definition, and mix multiple intents in the same section.
Entity-first design fixes that by making the page readable to a retrieval system before it tries to be elegant to a human.
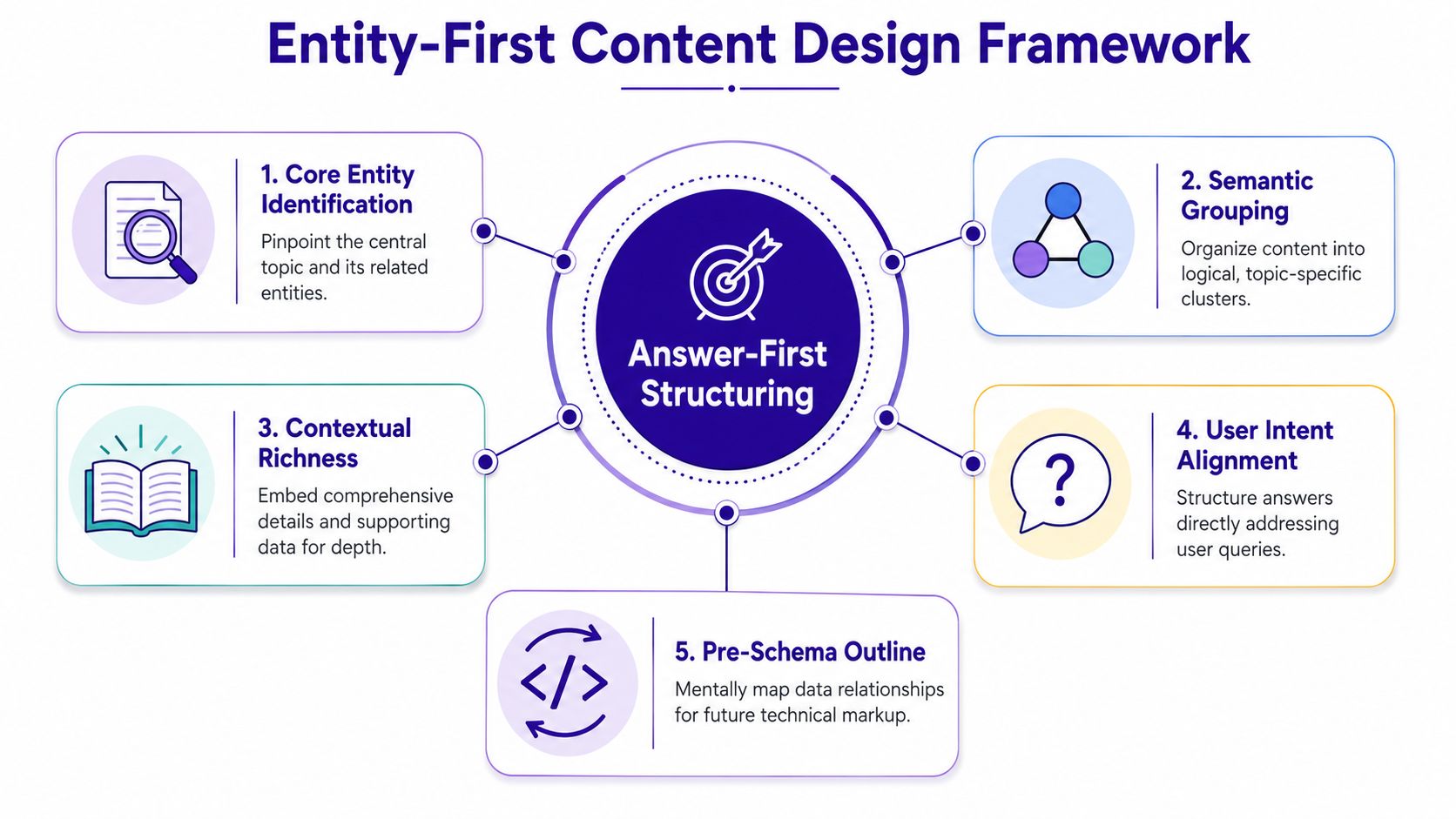
Start with the answer block
Put a 60–100 word direct answer immediately after the H1 or within the first part of a section. Then support it with bullets, examples, or a short comparison. This isn't a style preference. It matches how retrieval-augmented systems pull concise, cite-worthy passages.
Content that follows a modular Answer-First structure has shown a 35–50% higher inclusion rate in AI-generated summaries than traditional narrative pages (benchmarks on Answer-First structuring).
A workable pattern looks like this:
- Question-led heading that mirrors the way a user would ask it.
- Direct answer block in plain English.
- Bullets or short steps that expand the answer.
- Support material such as definitions, examples, edge cases, or data.
- Internal semantic links to related entities and supporting pages.
Many teams overcomplicate things. They hear “entity-first” and start stuffing related terms everywhere. Don't. The job is to create semantic clarity, not density for its own sake.
Build sections that can stand alone
Each section should be self-contained enough that a model can quote it without reading the entire page. That means the section has to identify its subject early, avoid pronouns with unclear references, and keep context local.
Use this checklist when editing:
- Name the entity early: Don't say “this approach” before naming the actual method.
- Match natural prompts: Use question-based H2s and H3s, not abstract labels like “Overview” or “Insights.”
- Keep support scannable: Bullets, tables, and short paragraphs are easier to extract accurately than dense narrative.
- Prefer plain language: Jargon-heavy definitions often miss the wording patterns models expect.
The editorial trade-off is real. Answer-first content can feel blunt if you only optimize for extractability. The fix is simple. Put the precision first, then layer nuance after it. Humans still get depth. Models get a clean citation target.
A strong AI-search page reads like a sequence of finished answers, not a single essay that happens to contain answers.
When teams rewrite old content, the biggest gains usually come from section surgery, not full rewrites. Keep the useful ideas. Rebuild the delivery. Shorten the lead-in, sharpen the headings, and make each block independently useful.
Implementing Technical Structured Data
Strong structure in the copy isn't enough. You also need to expose that structure in code. If the page says one thing to a reader and another thing to a crawler, the crawler wins.
That's why schema and HTML hierarchy belong in the core workflow, not in a cleanup sprint after publishing.
Use schema that matches extraction patterns
For most informational pages, the base stack is straightforward: Article, FAQPage, and when applicable, HowTo. Those schemas don't make weak content strong, but they reduce ambiguity around page type, answer structure, and instructional flow.
Large-scale audit benchmarks show that pages with properly implemented FAQ schema and bulleted lists have a 2.5x higher probability of being cited in LLM responses than unstructured text (schema and citation benchmark details).
The implementation details matter:
- Article schema: Use it on guides, explainers, and long-form resources that establish the main subject and authorship context.
- FAQPage schema: Use it only when the on-page questions and answers are present and visible.
- HowTo schema: Use it when the page contains a genuine step sequence, not just advice disguised as steps.
Bad schema creates its own problems. Inflated FAQ blocks, hidden answers, and mismatched entities make the page look less trustworthy, not more.
Fix the page layer, not just the markup
Schema works best when the HTML is already disciplined. Keep heading hierarchy rigid. H2 should introduce the main subtopic, H3 should nest under it, and H4 should only appear when the structure requires another level.
Short paragraphs are not cosmetic here. They're part of machine readability. Paragraphs that run too long, sentences that stack too many clauses, and sections that depend on the surrounding article make extraction harder.
Common failure points I see in audits:
| Issue | What happens | Better fix |
|---|---|---|
| FAQ schema added to a page with weak section structure | The page is technically marked up but still hard to extract | Rewrite each Q&A into clean, self-contained answer blocks |
| Generic headings like “Benefits” or “Conclusion” | The model gets less semantic guidance | Rewrite headings as explicit questions or entity labels |
| Lists used without lead-in context | The bullets lack standalone meaning | Add a one or two sentence setup before the list |
| JavaScript-heavy rendering of key content | Retrieval may miss the section entirely | Ensure the primary answer content is server-delivered and visible |
Later in the workflow, the technical layer needs ongoing checks. Teams often use a mix of crawler audits, schema validators, and workflow tools. One option is Nuwtonic, which combines GEO audits, on-page issue detection, and reviewable fixes in one workspace so teams can push structural corrections without manually rebuilding every page.
A quick walkthrough of AI-oriented technical SEO helps clarify what to look for before you deploy:
Building Source Authority and Citation Hygiene
AI search selects pages it can verify fast. Citation hygiene is the layer that makes verification easy.
I see the same pattern in GEO audits. A page can be well written and structurally clean, then still lose citations because the evidence chain is weak. No named author. No source behind a key claim. A stat quoted from a secondary blog instead of the original publisher. Those are not style issues. They increase citation risk, and AI systems tend to avoid risk.
What citation-worthy content actually looks like
Citation-worthy pages make provenance obvious. The claim is clear, the owner of the claim is visible, and the supporting source is close to the statement it supports. If an editor or model has to hunt for proof, the page becomes less useful as a source.
In practice, four habits matter most:
- Support assertions at the point of use: Put evidence next to the claim, not buried at the bottom of the page.
- Show who is responsible for the content: Named authors, expert reviewers, and editorial dates help establish accountability.
- Use current supporting sources: A solid argument can weaken if the references are outdated, superseded, or no longer available.
- Link to primary material where possible: Original research, official documentation, and first-party data usually carry more weight than recycled summaries.
The pages that get cited usually reduce verification time.
That changes how I build and revise content for AI search. Instead of asking whether a paragraph sounds authoritative, I ask whether each important claim has an inspectable chain of support. That includes the source itself, the author identity, and the freshness of the evidence. Nuwtonic helps operationalize that review by turning unsupported claims, weak outbound references, and missing attribution into fixable tasks instead of leaving them buried in editorial QA.
What weakens trust
Several patterns lower citation potential even when the writing is strong:
- Anonymous claims: Advice appears without a named author, reviewer, organization, or source.
- Second-hand sourcing: The page cites another article summarizing research instead of the original study or official documentation.
- Stale references: The recommendation is current, but the proof points are years old or no longer accessible.
- Precision without provenance: Exact percentages, dates, or rankings appear without showing where they came from.
- Broken citation chains: Outbound links resolve to soft 404s, redirects, login walls, or pages that do not support the claim.
There is a trade-off here. Adding evidence to every sentence can make a page harder to read. The fix is not to overload the copy. It is to identify the claims an AI system is most likely to extract, then make those claims easy to verify. High-value statements need visible sourcing. Commodity statements do not.
Teams that publish at scale should treat citation hygiene as an ongoing workflow, not a final polish step. Review outbound links, refresh aging references, confirm that expert bylines still reflect real ownership, and replace unsupported precision with either evidence or simpler wording. That is how source authority becomes repeatable instead of accidental.
Ensuring Technical Readiness and AI Indexing
A page can be well written, well sourced, and still miss AI visibility because the delivery layer is weak. Slow rendering, unstable mobile performance, poor crawl paths, and inconsistent canonical signals all reduce the chance that an AI system treats the page as dependable.
That's why technical readiness isn't a separate SEO concern. It directly affects whether your content is even considered for extraction.

The performance threshold that matters
By early 2025, Google documentation established that pages scoring above 90 on Lighthouse Performance were preferred for AI Overviews, and faster sites had a 25% higher likelihood of being cited than slower ones (Google AI Overview preference and Lighthouse threshold). That turned performance from a quality signal into a practical inclusion threshold.
The implication is straightforward. If your page is slow, unstable, or clumsy on mobile, content quality alone won't rescue it.
Focus on these areas first:
- Performance score: Push the page above the threshold where possible.
- Mobile rendering: The answer block, headings, and schema-relevant content must remain accessible on small screens.
- Stable layout: If elements shift while loading, extraction reliability drops.
- Clean canonicalization: Duplicate or conflicting canonicals muddy which URL should be cited.
Delivery problems that block inclusion
Technical readiness often fails in less obvious ways. Teams obsess over Core Web Vitals, then leave the answer content buried in expandable modules, delayed by client-side scripts, or fragmented across tabs.
Check the page like a retrieval system would:
| Check | Good state | Bad state |
|---|---|---|
| Primary answer visibility | The answer appears immediately in rendered HTML | The answer appears only after interaction or script execution |
| Mobile readability | Headings, bullets, and summaries remain intact | Content collapses into awkward cards or hidden panels |
| Crawl consistency | Canonical, metadata, and internal links point clearly to one target page | Variants compete or conflict |
| Content freshness pathway | The page is easy to revise and republish | Updating requires manual rebuilds across templates |
Fast pages don't just load better. They give crawlers and retrieval systems fewer reasons to skip or truncate your content.
When teams optimize content for AI search, they often stop at copy and schema. The stronger move is to test the entire rendered experience. Open the page on mobile. View source. Validate structured data. Check canonical consistency. If a machine can't access the final answer cleanly and quickly, the page is only partially optimized.
Monitoring AI Visibility and Iterative Remediation
AI search optimization breaks when teams treat publishing as the finish line. Models change. Prompt patterns shift. Competitors reshape their pages. Your own article ages.
The operating model has to be iterative. Track what gets cited, compare that against the prompts that matter to your audience, and patch the pages that underperform.
Track citations at the URL level
Brand mention tracking isn't enough. You need to know which specific URL gets cited, for which prompt type, and on which model surface. Otherwise, you can't tell whether the homepage is soaking up visibility that should belong to a product page, or whether a competitor's comparison page is winning because your structure is weaker.
A useful monitoring view includes:
- Prompt cluster: Questions grouped by intent, not just by wording.
- Cited URL: The exact page surfaced by the AI system.
- Citation context: Whether the page appears as a direct source, a supporting source, or not at all.
- Gap pattern: Which entities or subtopics competitors cover more cleanly.
For teams building a repeatable process, a toolset that connects prompt tracking to remediation is more useful than standalone monitoring dashboards. For example, AI visibility tracking tools are most helpful when they show citation gaps at the page level and feed those findings into revision queues.
Run a remediation loop
Most fixes after monitoring are structural, not dramatic rewrites. Think in short cycles.
Identify the miss
- The page isn't cited for an expected prompt cluster.
- Or it's cited inconsistently across models.
Diagnose the reason
- Weak answer block.
- Missing supporting entity.
- Thin FAQ support.
- Technical delivery issue.
- Outdated examples or stale source layer.
Patch the page
- Rewrite the opening answer.
- Add a missing comparison table.
- Clarify heading language.
- Expand one self-contained section.
- Refresh examples and references.
Recheck the result
- Watch whether citation behavior changes across the next review cycle.
- Compare against competing pages, not just your own baseline.
The teams that hold visibility longest are rarely the ones publishing the most. They're the ones running cleaner maintenance. They know which URLs matter, which prompts matter, and which fixes move a page from “present” to “preferred source.”
Frequently Asked Questions about AI Search Optimization
AI search visibility usually breaks in execution, not in strategy. Teams know they need clear answers, schema, authority signals, and clean delivery. The miss happens when those pieces are handled in separate workflows and no one owns the full chain from page structure to citation monitoring.
FAQ Quick Reference
| Question | Answer Summary | Nuwtonic Automation |
|---|---|---|
| Does llms.txt replace schema markup? | No. Use it as a supporting file, alongside schema and crawlable page content. | Keeps technical checks, content tasks, and AI visibility work in one operating flow. |
| Is answer-first writing enough on its own? | No. Pages also need machine-readable markup, strong source support, and reliable delivery. | Connects content changes to audit findings and execution queues. |
| Should every page use FAQPage schema? | No. Use it only when the page includes visible question-and-answer content. | Flags markup opportunities and mismatches during audits. |
| How often should AI-search content be refreshed? | Refresh when the topic changes, stronger sources appear, or citation share shifts to competing pages. | Supports recurring update workflows and prioritized fix lists. |
Does llms.txt matter right now
Yes. It belongs in the stack, but it should stay in proportion.
As noted earlier, current guidance treats llms.txt as a helpful access and discovery signal, especially when paired with clean schema and well-structured pages. The file does not have a reliable standalone lift benchmark, so it should not be sold internally as the fix for AI visibility.
The practical approach is simple. Publish it if your team can maintain it accurately. Then spend more time on the pages that need to be cited.
What's the right order of operations
Start with the citation target, not the directive file.
A workable order looks like this:
- Fix the page answer. Make the primary response easy to extract and easy to trust.
- Fix the machine-readable layer. Validate schema, heading structure, and on-page Q&A alignment.
- Fix delivery. Check rendering, canonicals, indexation, and mobile behavior.
- Add secondary AI-access signals. Include files like llms.txt after the page can already compete.
This order matters because AI systems still rely on content they can parse, attribute, and retrieve cleanly. A weak page with extra directives stays weak.
Why do strong pages still miss AI citations
The usual failure points are narrower than teams expect.
Some pages explain the topic well but never state the answer cleanly enough for extraction. Others have a strong editorial layer and a messy technical one. Some look credible to a human reader but lack enough source support, entity coverage, or citation-friendly formatting to be selected consistently.
I see this often on pages that were written for rankings alone. They can earn traffic and still lose AI citations because the answer is buried under scene-setting, comparisons are incomplete, or supporting evidence is too thin. Good GEO work fixes retrieval, interpretation, and trust at the same time.
Should teams build separate AI-search pages
Usually no.
In most cases, the better move is to upgrade existing high-intent URLs that already have topical relevance, links, and search history. That keeps authority consolidated and reduces duplication risk across similar intents.
Create a separate page only when the query deserves its own entity set, its own answer format, or a meaningfully different commercial angle. If the new page cannot justify a distinct intent, it usually fragments performance instead of improving it.
If your team wants one system for auditing pages, identifying citation gaps, and turning fixes into reviewable tasks, Nuwtonic is built for that workflow. It connects AI visibility tracking, technical audits, content operations, and deployment controls so GEO work reaches production instead of stopping at reporting.


