Here's the deal. For the last 8 years, I have spent my days tearing apart digital content to figure out why machine learning models misinterpret it. Ever wonder why your content isn't getting picked up by AI overviews or retrieval-augmented generation (RAG) systems? The culprit is almost always ambiguity.
Many content creators overlook the importance of data hygiene — without it, even the best content can fall flat. We write for humans, using elegant transitions, pronouns, and varied vocabulary. But to a Large Language Model (LLM), that elegance is a maze of floating references and undefined scope. If you want your content extracted, cited, and grounded reliably, you have to treat your text as a structured dataset.
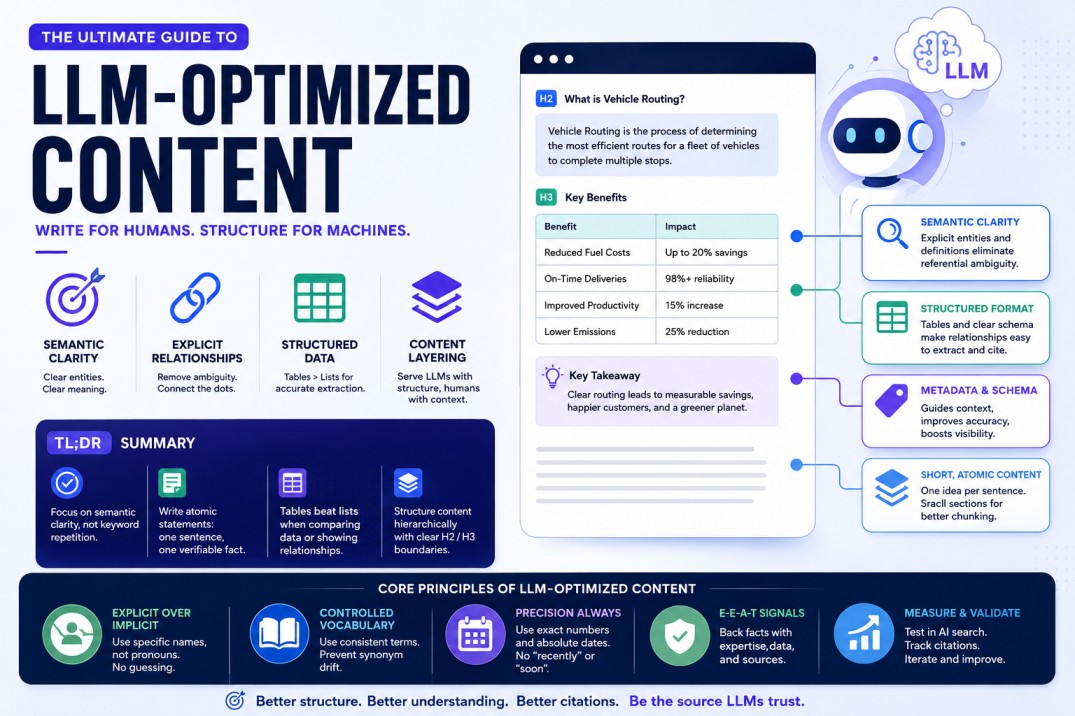
TL;DR Summary
• Semantic Clarity wins: Stop obsessing over keyword repetition and start focusing on explicit entity relationships.
• Atomic Statements are mandatory: One sentence should equal one verifiable fact.
• Tables beat lists for relationships: When comparing data, tables provide the rigid schema LLMs need to extract accurate citations.
• Content Layering is the balance: Serve the LLM with structured summaries, and serve the human with engaging narrative.
Key Takeaways
Replace vague pronouns with explicit entity names to eliminate referential ambiguity.
Use a controlled vocabulary to prevent synonym drift across your site.
Implement explicit metadata tagging and schema to guide contextual extraction.
Structure your content hierarchically with clear H2 and H3 boundaries.
Table of Contents
The Anatomy of LLM Extractability
Core Strategies to Eliminate Content Ambiguity
Formatting Content for Flawless Extraction
Diagnosing and Fixing Common Extraction Failures
Measuring and Validating Extractability
FAQ Section
Sources and References
The Anatomy of LLM Extractability
Alright, let's break this down. Extractability is not about dumbing down your writing; it is about removing the guesswork. When an LLM processes your page, it tokenizes the text and attempts to map relationships between subjects, verbs, and objects.
Why Semantic Clarity Matters More Than Keywords
I've seen too many teams fixate on keyword density when improving tokenization is the real difference maker for LLM extractability. Semantic clarity means that every term you use has a single, unmistakable meaning within its context.
When you use "the platform" in paragraph one and "our software" in paragraph three, human readers know you mean the same thing. An LLM might treat them as two distinct entities. This fragmentation destroys your chances of being featured as a definitive answer. Mastering AI SEO optimization techniques requires a shift from keyword matching to entity resolution.
The Cost of Referential Ambiguity
Referential ambiguity occurs when words like "it," "they," "this," or "former/latter" lose their anchor.
Consider this scenario: I once worked with a SaaS company whose technical documentation was failing miserably in their internal AI search. Users would ask, "How do I reset the API key?" and the LLM would output instructions for resetting a user password. Why? Because the documentation said, "Navigate to the API settings and the User Profile. Click on it to reset your credentials." The LLM could not reliably resolve what "it" referred to.
Balancing Human Readability with Machine Parsing
How can I balance human readability with LLM extractability? This is the most common question I get from content teams. The answer is content layering.
You do not have to write like a robot. Instead, use structured elements (like bolded definitions, summary boxes, or explicit bullet points) to anchor the facts, and use the surrounding paragraphs for human narrative. The LLM will latch onto the high-density, structured zones, while human readers will appreciate the context.
Core Strategies to Eliminate Content Ambiguity
Simplicity is key; most ambiguities can be resolved with straightforward language and clear structure. Let's look at the mechanical fixes you can apply today.
Enforcing a Controlled Vocabulary
A controlled vocabulary is a predefined list of terms your brand uses to describe its core concepts. If you sell a "Content Management System," do not interchangeably call it a "publishing tool," a "web platform," and a "CMS" within the same article without explicitly defining that they are the same entity.
Ambiguous Approach (Synonym Drift) | Extractable Approach (Controlled Vocabulary) |
|---|---|
"Our vehicle routing tool helps fleets. The dispatch software reduces delays." | "Our Vehicle Routing Tool (also referred to as dispatch software) helps fleets reduce delays." |
"Customers love the new feature. Users say it saves time." | "Enterprise Customers report that the Automated Tagging Feature saves them 5 hours per week." |
Writing Atomic Statements
An atomic statement contains exactly one idea, one subject, and one action. Compound sentences with multiple clauses force the LLM to parse complex dependency trees, increasing the risk of hallucination during extraction.
• Bad: "The new update, which rolls out on Tuesday unless you are on the legacy plan, fixes the bug and introduces dark mode."
• Good: "The v2.4 update rolls out on Tuesday, October 12th. This update fixes the login bug. This update introduces dark mode. Legacy plan users are excluded from this rollout."
Precision in Numbers and Temporal Data
Never use relative time markers like "currently," "recently," or "soon." In three years, "recently" will be a lie, and the LLM will extract outdated information. Use absolute dates (e.g., "As of Q3 2026").
The same applies to numbers. Instead of saying "a massive increase," say "a 42% increase." Numeric precision grounds the model in verifiable reality, which heavily supports the Importance of EEAT for AI SEO.
Formatting Content for Flawless Extraction
The visual structure of your page is the blueprint the LLM uses to understand relationships. If your formatting is messy, your extraction will be messy.
Should I Write Shorter Sections to Improve LLM Readability?
Yes, absolutely. Shorter sections bounded by descriptive H3 headers act as semantic boundaries. When an LLM chunks text for a vector database, a 1,000-word wall of text might get split arbitrarily, separating a concept from its context.
By writing shorter, tightly scoped sections (200-300 words maximum per heading), you ensure that when the text is chunked, the header, the context, and the facts stay bundled together.
Table Formatting vs. Lists for LLM Citations
When should you use a list, and when should you use a table? This is a critical distinction for Formatting content for LLM readability.
Format Type | Best Used For | LLM Extraction Behavior | Citation Accuracy |
|---|---|---|---|
Numbered Lists | Sequential steps, rankings, chronological processes. | Extracts as a rigid sequence. Good for "How-to" queries. | High for procedural extraction. |
Bullet Points (•) | Features, benefits, unordered collections. | Extracts as a set of related items belonging to the parent header. | Medium. Good for summaries, but lacks relational depth. |
Markdown Tables | Specifications, pros/cons, multi-variable comparisons. | Binds the column header to the row value explicitly (Entity A has Attribute B). | Extremely High. The gold standard for factual grounding. |
If you are comparing two software tools, do not write a paragraph contrasting them. Build a table. The LLM will parse the grid and confidently cite the exact differences.
LLM Structured Output Best Practices
When optimizing for structured output, you need to provide explicit key-value pairings in your text.

• Use bolding for keys: Price: $49/month.
• Define constraints explicitly: State exactly what a feature does not do. LLMs struggle with implicit exclusions.
• Keep formatting consistent: If you format one product review with a specific set of subheadings, use the exact same subheadings for the next product.
Diagnosing and Fixing Common Extraction Failures
Even with good intentions, things go wrong. Let's look at the most common failure points I see when auditing content for AI platforms.
Resolving Pronoun and Entity Confusion
I mentioned this earlier, but it bears repeating. Go through your draft and highlight every "it," "this," "that," "these," and "those." Replace at least 70% of them with the actual noun. It feels slightly repetitive to a human, but it acts as an anchor chain for an LLM.
Common Formatting Issues in LLM Generated Text
Ironically, when humans use LLMs to generate content, the output itself often suffers from formatting issues that make it hard for other LLMs to extract later.
• Hallucinated table syntax: Missing pipes (|) in markdown tables break the parser.
• Inconsistent list markers: Mixing asterisks, hyphens, and numbers confuses the hierarchy.
• Orphaned headers: An H3 with no text beneath it, followed immediately by another H3.
Always validate your markdown. Clean, valid HTML or Markdown is the universal language of clean data ingestion.
Handling Edge Cases and Exceptions
LLMs are notoriously bad at handling "unless" or "except" clauses if they are buried in a paragraph. If you have conditional logic, pull it out into its own clearly labeled section.
• Standard Rule: All users receive 50GB of storage.
• Exceptions: Enterprise users receive 500GB. Trial users receive 5GB.
By separating the rule from the exception, you prevent the LLM from blending the numbers into a hallucinated average.
Measuring and Validating Extractability
You cannot improve what you cannot measure. How do you know if your ambiguity reduction actually worked?
Designing an Extraction Test Workflow
Take your original content draft.
Feed it into an LLM (like GPT-4 or Claude) with a zero-shot prompt: "Extract the pricing, limitations, and setup steps from this text into a JSON format."
Review the output. Did it miss a step? Did it assign the wrong price to the wrong tier?
Revise the text using the strategies above (atomic statements, tables, entity names).
Run the prompt again.
When the LLM returns a flawless JSON object on the first try, your content is highly extractable.
Utilizing Schema and Metadata Tagging
Metadata tagging is the invisible layer of ambiguity reduction. Implementing robust JSON-LD schema (like FAQPage, Article, or SoftwareApplication) gives the LLM a deterministic map of your page before it even reads the text. It confirms that the sequence of numbers on the page is, in fact, a price, and not a version number.
Cross-Document Consistency Management
Ambiguity doesn't just happen on a single page; it happens across your entire domain. If Page A says "Nuwtonic automates SEO" and Page B says "Nuwtonic is a manual SEO assistant," you have created a semantic collision.
Maintain an internal knowledge graph or a central glossary. Every piece of content must align with this central source of truth. If the facts conflict, the LLM will either guess, hallucinate, or drop your brand entirely in favor of a more consistent competitor.
FAQ Section
How do I write content so an LLM extracts the right facts?
Focus on atomic statements. Write one idea per sentence, use explicit entity names instead of pronouns, and format relationships into markdown tables.
What kinds of ambiguity most often confuse LLMs?
Referential ambiguity (unclear pronouns like "it" or "they"), temporal ambiguity (using "recently" instead of actual dates), and scope ambiguity (failing to explicitly state when a rule or feature does not apply).
How specific should terminology be?
Extremely specific. Establish a controlled vocabulary and stick to it. Do not use three different synonyms to describe your core product just to make the writing sound varied.
Is it better to define terms inline or in a glossary?
Both. Define the term explicitly the first time you use it inline (e.g., "Tokenization is the process of..."), and maintain a central glossary on your site to ensure cross-document consistency.
Do numbers, dates, and units really matter that much?
Yes. Vague quantifiers ("a lot," "faster," "soon") cannot be grounded as facts. Exact numbers ("42%," "2.5 seconds," "October 2026") provide rigid data points that LLMs confidently extract and cite.
Sources and References
• Analysis of LLM parsing behaviors and semantic clarity based on proprietary testing of RAG systems (2024-2026).
• Standardized Markdown and JSON-LD structured data documentation principles for machine readability.
• Expert consensus on entity resolution and referential ambiguity in Natural Language Processing.


